Dosya Sistemi Nedir?
Dosya sistemleri, kullanıcılara, verileri, bir dosya ve dizin hiyerarşisi içerisinde saklama mekanizması sunar. Bir dosya sistemi, yapısal veriler ile kullanıcı verilerini, bilgisayarın onları nerede bulacağını bilebileceği şekilde organize eder.
Dosya sistemleri, bir floppy diske bir veriyi kaydetmekte veya binlerce dosyadan onlarcasını bir depolama dizisinde saklamakta kullanılan belirli izlek ve yapılara sahiptir. Her dosya sistemi bileşeninin kendine özgü bir boyutu vardır.
Veri Kategorileri
Dosya sisteminde temel olarak 5 çeşit veri kategorisi vardır. Dosya sistemi, içerik, metadata, dosya ismi ve uygulamalardır. Dosya sistemi kategorisi genel dosya sistemi bilgilerini içerir. Bu kategorideki veriler, size belirli veri yapılarının nerede bulunduğunu ve bir veri biriminin ne büyüklükte olduğunu söyleyebilir. Bu kategorideki veriyi, dosya sisteminin bir haritası gibi düşünebiliriz. İçerik kategorisi, bir dosyanın asıl içeriğini oluşturan verileri içerir. Dosya sistemindeki çoğu veri bu kategoriye aittir ve standart büyüklükte konteynerler koleksiyonu şeklinde organize edilmişlerdir. Her dosya sistemi bu konteynerlere değişik isimler vermişlerdir. Cluster ve blok gibi, ancak biz şimdilik veri birimleri terimini kullanacağız.
Metadata kategorisi bir dosyayı tanımlayan verileri içerir. Bu kategori, dosya içeriğinin nerede saklandığı, dosyanın boyutu, dosyaya en son ne zaman yazıldığı veya erişildiği ve erişim kontrol bilgileri gibi bilgiler içerir. Bu kategoride dosyanın içeriği bulunmaz ve dosya ismi de bulunmayabilir. Bu kategorideki veri yapılarına FAT dizin girdileri, NTFS MFT girdileri, UFS, Ext3 ve Exy4 inode yapıları örnek verilebilir. Dosya ismi kategorisi veya insan ara yüzü kategorisi, her dosyaya bir isim atayan veriler içerir. Çoğu dosya sisteminde bu veriler, bir dizinin içeriğinde bulunur ve ilgili metadata adresleriyle birlikte bir dosya ismi listesi şeklindedir. Uygulama kategorisi, diğer özellikleri sağlayan verileri içerir. Bu verilere bir dosyaya yazma veya dosyadan okuma sırasında gerek duyulmaz ve çoğu durumda, dosya sistemi tanımlamasında bulunmaz. Bu kategorideki verilere örnek olarak; kullanıcı kota istatistikleri ve dosya sistemi günlükleri örnek verilebilir. Aşağıda bütün bu kategorilerin birbirleriyle olan ilişkileri gösterilmiştir.
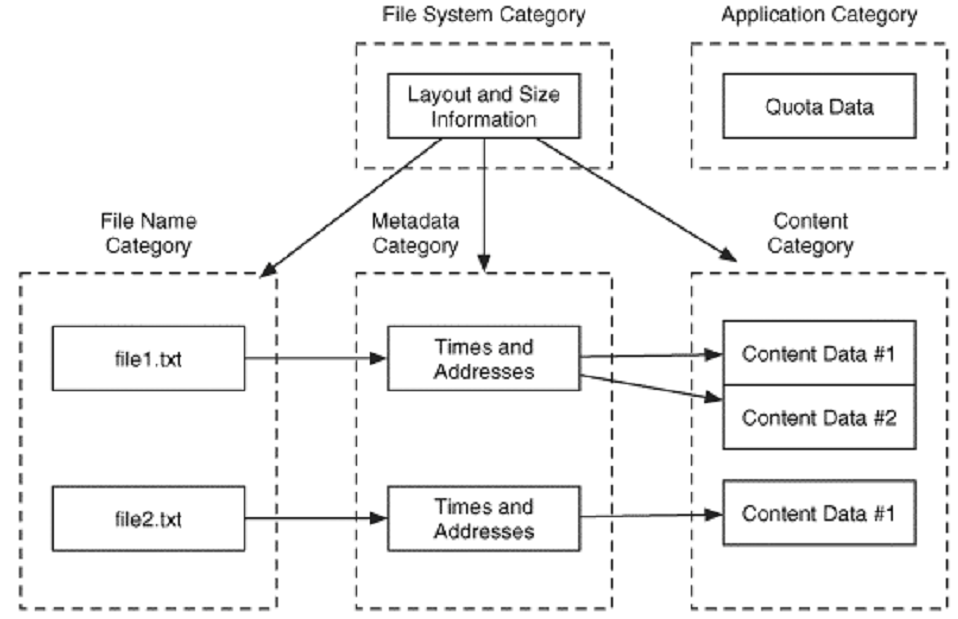
Elzem - Elzem Olmayan Veri
Elzem dosya sistemi verisi, dosyalara erişim ve kayıt için gerekli olan verilerdir. Bu tip verilere örnek olarak; dosya içeriğinin tutulduğu adresler, dosyanın ismi ve bir isimden bir meta data yapısına olan işaretçi verilebilir. Elzem olmayan veri ise orada kolaylık için bulunan ancak temel fonksiyonlar ve dosyaya erişim veya yazma için gerekli olmayan verilerdir. Erişim zamanı ve izinler bu tip verilere örnektir.
Dosya Sistemi Kategorisi
Dosya sistemi kategorisi bir dosya sisteminin nasıl kendine has olduğunu ve diğer önemli verilerin nerede olduğunu tanımlar. Bu bilgilerle, dosya sisteminin boyutuna bağlı olarak değişen, diğer verilerin yeri bulunabilir. Dosya sistemindeki verilerin analizi tüm dosya sistemi analizleri için gereklidir çünkü bu aşamada diğer kategorilerdeki veri yapılarının yeri bulunur. Genel düzen bilgisinin haricinde, bu kategorinin analizi, dosya sisteminin versiyonunu, dosya sistemini yaratan uygulamaya, yaratma tarihini ve dosya sistemi etiketini de gösterir.
İçerik Kategorisi
İçerik kategorisi, dosya ve dizinlere veri kaydedebilmesi için atanmış depolama yerlerini içerir. Bu kategorideki veriler veri birimi diye adlandırdığımız ancak farklı dosya sistemleri tarafından farklı farklı isimlendirilen (cluster veya blok) eşit büyüklüklü gruplardan oluşur. Bir veri birimi atanmış veya atanmamış durumda olabilir. Bir dosya yaratılacağı zaman veya var olan bir dosyanın boyutu arttırıldığı zaman, işletim sistemi bir atanmamış veri birimi arar ve onu ilgili dosyaya atar. Bir dosya silindiğinde ise o veri biriminin içeriğini silmektense, o veri biriminin durumunu “atanmamış” hale getirir.
Genel bilgiler
Mantıksal dosya sistemi adresi:
Volume sistemleri, volume’ler yaratarak, volume’ün başlangıcıyla ilişkili olan mantıksal volume adresleri atar. Dosya sistemleri mantıksal volume adresleri kullanır, ancak mantıksal dosya sistemi adresleri de atarlar çünkü bir veri birimi oluşturmak için ardışık sektörleri gruplamaları gerekir. Çoğu dosya sisteminde, volume’daki her sektör bir mantıksal dosya sistemi adresine atanır. Bu duruma uymayan dosya sistemlerine örnek olarak FAT verilebilir. Aşağıda 17 sektör ve bu sektörlerin mantıksal volume adreslerinden oluşan bir volume gösterilmiştir. Altındaysa mantıksal dosya sistemi adresleri görülmektedir.

Bu hayali dosya sistemi, her biri 2 sektörden oluşan veri birimleri yaratmış ve 4.sektöre kadar adres ataması yapmamıştır. Bu çok küçük dosya sistemi 15. Sektörde bitmekte ve 16. sektör “volume slack” olarak adlandırılmaktadır.
Atama Stratejileri
Eğer bir dosya ardışık veri birimlerine sahip değilse, ona “”fragmented” denir. Dosyalara veri birimi tahsisinin birçok değişik yöntemi vardır.
Bir “ilk kullanılabilir” stratejisi, veriyi yerleştirmek için ilk veri biriminden başlayarak kullanılabilir (boş) bir veri birimi arar. Bulduğu ilk boş birime, veriyi yazar. İkinci bir veri için tekrar ilk veri biriminden başlayarak arama yapar. Bu şekilde “fragmented” dosya sayısı artar. Ayrıca dosyanın en başındaki silinmiş verilerin üzerine diğer algoritmalara göre daha çabuk yazılır. Bu yüzden bu algoritmayı kullanan bir cihaz araştırılıyorsa, dosya sistemi sonunda bulunan silinmiş veriyi kurtarma olasılığı daha yüksektir. Aşağıdaki şekilde bu algoritma kullanılırsa, 1 no’lu veri birimi, sıradaki verinin yazılacağı yer olacaktır.
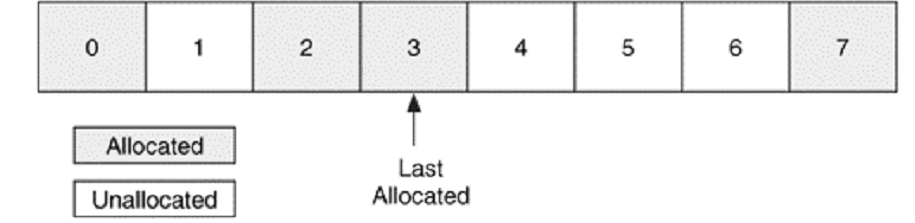
Benzer bir atama stratejisi “sonraki kullanılabilir” dir. Bu stratejide dosya sisteminin en başı yerine, en son atanmış olan birimin bir sonraki biriminden itibaren arama yapılır. Örneğin yukarıdaki şekilde sıradaki veriyi yerleştirmek için 4 numaralı birimden itibaren arama yapılmaya başlanır.
Diğer bir strateji ise “best fit” dir. Burada yazılacak toplam veri büyüklüğü kadar büyüklükte ardışık birimler aranır. Bu strateji yazılacak veri miktarı biliniyorsa iyidir fakat veri boyutu büyüdükçe sorunlar yaşanır. Eğer verinin tamamını yazacak alan bulunamazsa önceki stratejilerden biri kullanılır. Örneğin yukarıdaki şekilde, 2 birimlik yazılacak verimiz varsa, veri, 4 ve 5. birimlere yazılır. 1 ve 4’e dağıtılmaz.
Hasarlı veri birimleri
Eski harddisklerde işletim sistemi, hasarlı veri birimlerine veri yazılmaması için bu tip veri birimlerini tespit ederek “hasarlı” olarak işaretleyebilirler. Modern harddisklerde ise bu işi yaparak hasarlı birimi bir yedek birimle değiştirir. Bu sayede dosya sistemi fonksiyonelliğine gerek kalmaz. Eğer dosya sistemi fonksiyonelliği bulunuyorsa bunu kullanarak veri gizlemek çok kolaydır. Çoğu tutarlılık kontrol aracı dosya sisteminin hasarlı olarak rapor ettiği veri birimlerinde doğrulama yapmaz. Bunun yanında bazı kullanıcılar, hasarlı olmayan bir sektörü de hasarlı listesine ekleyerek içerisine veri gizleyebilir. Çoğu imaj alma aracı, hasarlı birimleri rapor eder. Bu sayede hasarlı birimler listesi ile bu rapor karşılaştırılarak, listeye manuel olarak eklenmiş birimler bulunabilir.
Analiz teknikleri
Veri birimi görüntüleme
Veri birimi görüntüleme, araştırmacının delilin bulunduğu adresi bildiği durumlarda kullanılan bir tekniktir. Bu tip analizin arkasındaki teori basittir. Araştırmacı, veri biriminin mantıksal dosya sistemi adresini girer ve tool, veri biriminin byte veya sektör adresini hesaplar. Daha sonra tool o yeri bularak veriyi okur.
Mantıksal dosya sistemi seviyesi araması
Bu teknik, delilin içeriğinin bilindiği fakat yerinin bilinmediği durumlarda kullanılır. Bir mantıksal dosya sistemi araması, her birimde belirli bir değeri veya kelimeyi arar. Ancak dosyalar her zaman ardışık birimlerde bulunmaz ve eğer aradığımız değer “fragmented”bir dosyanın ardışık olmayan iki veri biriminde saklanıyorsa, bu arama ile aradığımız değeri bulamayız.
Veri birimi atama durumu
Eğer delilin bulunduğu yeri bilmiyorsak fakat atanmamış bir alanda olduğunu biliyorsak bu teknik kullanılır. Bazı tool’lar tüm atanmamış birimleri ayrı bir dosya içerisine ayırabilirken, diğerleri ise analizlerini sadece atanmamış alanlarda yapabilirler. Eğer sadece atanmamış alanı incelerseniz, burada ham datalar olduğu ve herhangi bir dosya sistemi yapısı olmadığı için dosya sistemi analiz araçlarını kullanamazsınız.
Tutarlılık kontrolü
İçerik kategorisindeki tutarlılık kontrollerinden birisi metadata kategorisindeki veriyi kullanır ve her atanmış veri birimi için o birimi gösteren bir tane metadata girdisinin olup olmadığını kontrol eder. Bu kullanıcının manuel olarak bir veri birimine ait atanma durumunu (atanmış-atanmamış) veri için bir isim vermeden değiştirmesini engellemek için yapılır.
İlgili bir metadata yapısı olmayan atanmış veri birimlerine “yetim veri birimi (orphan data unit)” denir. Örneğin aşağıdaki şekilde 2 ve 8 numaralı veri birimleri atanmıştır. Veri birimi 2’yi gösteren herhangi bir metadata girdisi olmadığı için o birim orphan’dır. Veri birimi 8’i gösteren 2 ayrı metadata girdisi vardır ve bu da çoğu sistem tarafından izin verilmeyen bir durumdur.

Diğer bir kontrol, hasarlı olarak listelenmiş bütün verileri inceler. Eğer elinizdeki hard disk imajı içerisinde hasarlı sektörler varsa, çoğu imaj alma yazılımı hasarlı veriyi sıfırlarla doldurur. Eğer hasarlı veriyi sıfırlarla dolduran bir yazılım kullandıysanız, hasarlı veri birimi listesinde bulunan veri birimleri sıfırla dolu olmalıdır. Eğer sıfır olmayan veri varsa, bunlarda kullanıcı tarafından gizlenmiş veri olabilir.
Wiping Teknikleri
Çoğu wiping veya “güvenli silme” yazılımı içerik kategorisinde çalışır ve bir dosyanın bulunduğu veya bütün kullanılmayan veri birimlerini sıfır veya rastgele değerlerle doldurur. Wiping yazılımlarının saptanması zordur. Eğer bütün atanmamış veri birimleri sıfır veya rastgele değerlerle doluysa bir wiping yazılımından şüphelenebilirsiniz. Eğer yazılım rastgele değerler yazmış veya var olan diğer veri birimlerini kopyalamışsa, yazılımın kullandığı, uygulama seviyesinde bir delil olmadan saptamak neredeyse imkânsızdır. Tabii ki, eğer sistemde bir wiping yazılımı bulursanız, kullanılıp kullanılmadığını ve son erişim zamanının ne olduğunu kontrol etmelisiniz. Eğer her dosya wipe edilmişse, dosyaların geçici kopyalarını da bulabilirsiniz.
Metadata Kategorisi
Metadata kategorisi tanımlayıcı verilerin bulunduğu kategoridir. Çoğu metadata yapısı bir sabit ya da dinamik uzunluklu tablolarda tutulur ve her girdinin bir adresi bulunur. Bir dosya silindiğinde, metadata girdisi atanmamış duruma getirilir ve işletim sistemi girdideki bazı değerleri wipe edebilir. Metadata kategorisinde yapılan analiz, belirli bir dosya hakkında daha detaylı bilgi edinmek veya belirli gereksinimlere sahip olan dosyaları aramak için kullanılır.
Genel bilgiler
Mantıksal dosya adresi
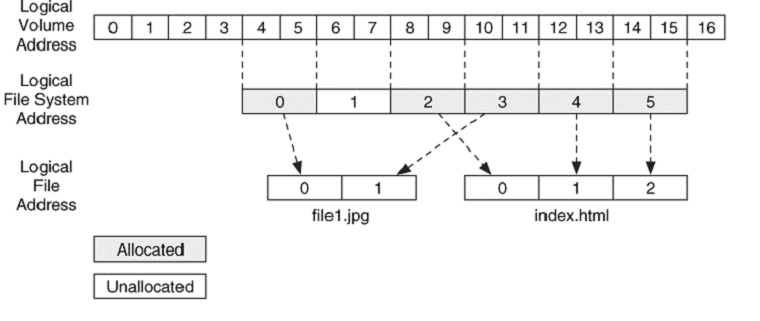
Bir dosyaya atanmış bir veri biriminin aynı zamanda mantıksal dosya adresi de vardır. Bir veri biriminin mantıksal dosya adresi atanmış olduğu dosyanın başlangıcıyla ilişkilidir. Örneğin, aşağıdaki örnekte 2 dosya için 5 veri birimi atanmıştır. Burada, mantıksal dosya sistemi adresi 1 olan birim atanmamıştır ve bu yüzden bir mantıksal dosya adresi bulunmamaktadır. Ayrıca mantıksal dosya sistemi adresi 2 olan birim, atanmış olduğu dosyanın ilk birimi olduğundan mantıksal dosya adresi 0 olmuştur.
Slack boşluğu
Bir dosya boyutunun veri birimi boyutunun katı olmadığı durumlarda slack boşluğu ortaya çıkar. Bir dosya, bir veri biriminin tümüne atanmalıdır. Eğer dosya veri biriminin küçük bir parçasına ihtiyaç duyuyorsa, son veri biriminin kullanılmayan byte’larına slack boşluğu denir.
Bazıları, kullanılmayan byte’ları wipe yapmaz bu yüzden slack boşluğu önceki dosyanın verilerini veya hafızadaki verileri içerebilir. Çoğu bilgisayarın dizaynında, slack boşluğunun 2 ilgi çekici alanı vardır. İlk alan, dosya sonu ile dosyanın sona erdiği sektörün sonu arasındadır. İkinci alan ise, dosya içeriği bulundurmayan sektörlerdedir.2 ayrı alan vardır çünkü hard diskler blok-tabanlıdır ve sadece 512 byte’lık sektör boyutunda kümeler şeklinde yazılabilir. Örneğin işletim sistemi diske sadece 100 byte yazamaz,512 byte yazmalı. Bu yüzden,100 byte’ı,412 bytelık veriyle doldurması gerekir. Slack boşluğunun ilk alanı ilgi çekicidir çünkü işletim sistemi, dosya içeriğini(örneğimizde 100 byte) ne ile doldurması gerektiğine karar verir. Genel metot, sektörü sıfırlarla doldurmaktır.
Bazı eski işletim sistemleri (DOS ve eski Windows’lar gibi) geri kalan sektörü hafızadaki verilerle doldurur. Bu slack boşluğu alanına RAM slack adı verilir ve günümüzde genel olarak sıfırlarla doldurulur. RAM slack from memory could reveal passwords and other data that was not supposed to be written to disk. Hafızadaki RAM slack, diskte yazılmış olması beklenmeyen şifre ve diğer verileri açığa çıkarabilir.
Slack boşluğunun ikinci alanı veri birimindeki kullanılmamış olarak kalan sektörlerdir. Bu alan ilgi çekicidir çünkü bazı işletim sistemleri sektörleri wipe’lar ve diğerleri bunu yapmaz. Eğer yapmazsa sektörler, önceden atandıkları dosyaya ait veriler içerebilir.
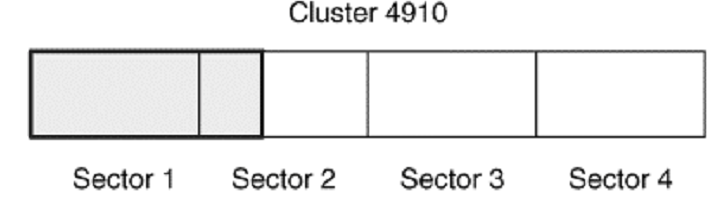
2048 BYTE’Lık cluster’lara ve 512 byte’lık sektörlere sahip bir NTFS dosya sistemini göz önüne alalım. Dosyamız 612 byte büyüklüğünde, bu yüzden, cluster’daki bütün 1.sektörü ve 2.sektörün 100 byte’lık kısmını kullanır. İkinci sektördeki kalan 412 byte işletim sisteminin seçtiği verilerle doldurulur. Üçüncü ve dördüncü sektörler ise işletim sistemi tarafından sıfırlarla wipe’lanabilir veya dokunulmaz ve silinmiş bir dosyaya ait verileri içerebilir. Bu durumu aşağıdaki şekilde görmekteyiz. Gri alanlar dosya içeriği ve beyaz boşluk, slack boşluğudur.
Metadata tabanlı dosya kurtarma
Silinmiş dosyaları geri getirmek(kurtarmak) için iki ana metot vardır; metadata tabanlı ve uygulama tabanlı. Metadata tabanlı kurtarma, silinmiş olan dosyaya ait metadata bilgisi duruyorsa işe yarar. Eğer metadata wipe edilmiş veya metadata yapısı yeni bir dosyaya atanmışsa, uygulama tabanlı teknikleri uygulamak gerekir. Aşağıda bu iki senaryo gösterilmiştir.
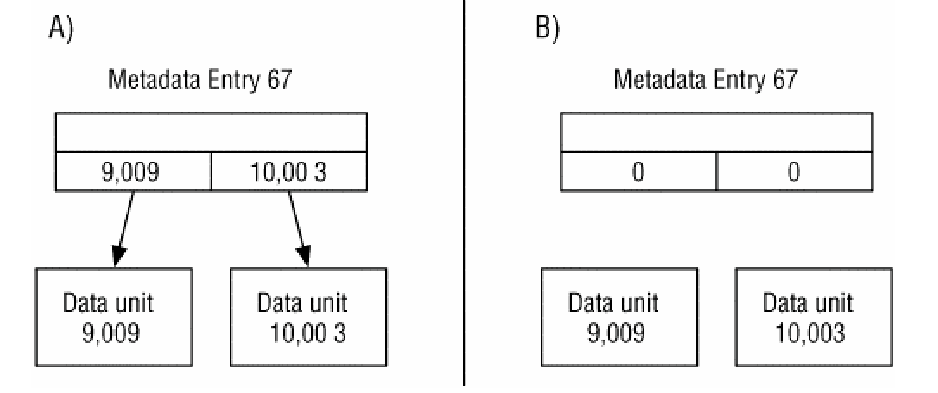
(A) yer alan şekilde atanmamış duruma geçirilen metadata girdisi hala veri birimi adresini içermekte ve biz kolaylıkla veri birimi içeriğini okuyabiliriz. (B) şeklinde ise işletim sistemi, dosya silindiğinde adres bilgisini de silmiştir. Metadata tabanlı kurtarma yaparken çok dikkatli olmalıyız çünkü veri birimleri ve metadata yapıları (veri birimleri yeni dosyalara atanmış olabileceği için) senkronize olmayabilir.
Silinmiş dosyaları kurtarırken, bir veri biriminin başka bir dosyaya atanıp atanmadığını tespit etmek zor olabilir. Örneğin, metadata girdisi 100’ün, veri birimi 1000’e atanmış olduğunu ve veriyi oraya kaydettiğini varsayalım. Daha sonra girdi 100’e ait dosyanın silindiğini ve girdi 100 ile veri birimi 1000’in ikisinin de atanmamış duruma getirildiğini varsayalım. Eğer metadata girdisi 200’de yeni bir dosya yaratılırsa ve bu dosya veri birimi 1000’i kullanırsa daha sonra o dosya da silinirse, biz sistemi analiz ederken aynı veri birimi adresini gösteren 2 tane atanmamış metadata girdisiyle karşılaşırız.
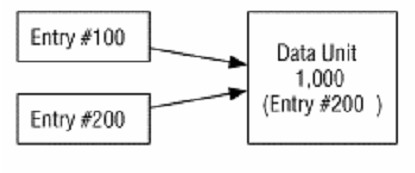
Bu durumda hangi girdinin dosyaya en son atandığına karar vermemiz gerekir. Bunu yapmanın bir metodu, her girdideki tarih bilgisine bakmaktır ki buna güvenemeyiz. Diğer bir metot ise, eğer metadata kaydını tutuyorsa, dosya tipini kullanmaktır. Örneğin metadata girdisi 200 bir dizin içinse, veri birimi 1000’deki içeriğe bakarak bunun dizin formatında olup olmadığını kontrol edebiliriz. Bir kurtarmanın doğru olup olmadığını, dosyayı, o dosyayı yarattığı düşünülen uygulamayla açarak kontrol edebiliriz.
Sıkıştırılmış ve sparse dosyalar
Bazı dosya sistemleri diskte daha az veri birimi kullanması için veri sıkıştırmaya izin verirler. Dosyalar için, sıkıştırma en az 3 seviyede olur. En üst seviyede bir dosya formatı içerisindeki veriler sıkıştırılır. Resim bilgisini saklayan verinin sıkıştırılmış olduğu fakat dosya header’ının sıkıştırılmadığı bir JPEG dosyası buna bir örnektir. Bir alt seviyede harici bir program bütün dosyayı sıkıştırır ve sıkıştırılmış halde yeni bir dosya yaratır. (WinZip gibi) Dosya kullanılmadan önce tekrar eski haline getirilmelidir.
Son ve en düşük seviyede ise dosya sistemi veriyi sıkıştırır. Bu durumda, dosyaya yazan uygulama, dosyanın sıkıştırılmış olup olmadığını bilmez. Dosya sistemleri tarafından uygulanan 2 temel sıkıştırma tekniği vardır. İlki dosyalarda kullanılan sıkıştırma tekniklerini kullanmak ve bu teknikleri dosyaların veri birimlerine uygulamak. İkinci teknik ise sıfırlarla doldurulacak fiziksel veri birimlerini atamamaktır. Sıfırlarla doldurulmuş veri birimlerini atlayan dosyalara sparse dosyalar denir. Aşağıdaki şekilde bir sparse dosyası görülmektedir.

Bunu gerçekleştirmenin birçok yolu vardır. Unix File System (UFS), bir bloğa ait adresin tutulduğu sahaya bir tane 0 yazar. Blok 0’a hiçbir dosya atanamayacağı için işletim sistemi, o bloğun sıfırlarla dolu olduğunu anlar.
Şifreli dosyalar
Dosya içeriği, dosyayı yetkisiz erişimlerden korumak için şifreli biçimde saklanabilir. Bir dosya diske yazılmadan önce, işletim sistemi dosyayı şifreler ve veri birimlerine şifrelenmiş metni koyar. İçerik olmayan veriler (dosya ismi ve son erişim tarihi gibi) genellikle şifrelenmez. Diğer bir dosya içeriği şifreleme yöntemi bütün volume’u şifrelemektir. Bu durumda, sadece içerik değil dosya sistemindeki bütün veriler şifrelenir. İşletim sisteminin bulunduğu volume ise bütünüyle şifrelenmez.
Analiz Teknikleri
Metadata Araması
Çoğu durumda metadatayı da analiz ederiz çünkü belirli bir metadata yapısını işaret eden bir dosya ismiyle karşılaşırız ve bu dosya hakkında daha fazla şeyler bilmeyi isteriz. Bu durumda metadatanın yerini bulmak ve veri yapısını işlemek zorundayız. Bu tekniğe ait prosedürler dosya sistemine bağlıdır çünkü metadata, dosya sistemi içerisinde değişik yerlerde olabilir. Aşağıda, veri birimi 371 içerisinde metadata yapılarının bulunduğu örnek bir dosya sistemi görülmektedir. Yazılımımız veri birimini okur ve 2 metadata girdisinin içeriğini gösterir. Bunlardan biri silinmiş bir dosya, diğeri ise atanmış bir dizindir.
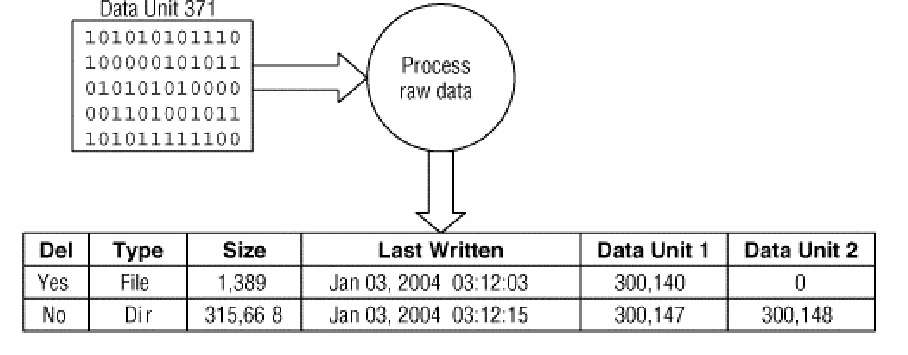
Mantıksal dosya görüntüleme
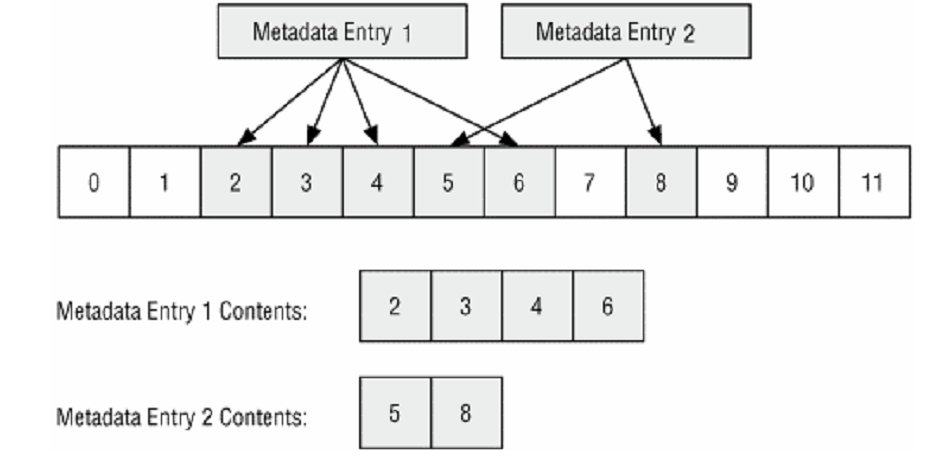
Metadata ’ya baktıktan sonra, dosyaya atanmış olan veri birimlerini okuyarak dosya içeriklerini görebiliriz. Bir dosyanın içeriğinde delil arıyorsak bunu uygularız. Bu süreçte, dosyaya atanmış olan veri birimlerini bulmak için metadata araması tekniğini, daha sonra da gerçek içeriği bulmak için içerik-görüntüleme tekniğini kullanırız. Aşağıdaki şekilde örnek olarak metadata girdisi 1 ve 2’ye atanan veri birimlerinin listesi görülmektedir.
Bu işlem sırasında slack boşluğunu da göz önünde bulundurmalıyız çünkü dosya son veri biriminin tümünü kullanmıyor olabilir. Slack boşluğu olup olmadığını, dosya boyutunu, veri birimi boyutuna bölerek bulabiliriz.
Mantıksal dosya arama
Önceki teknik belirli bir dosyanın içeriğine bakmak istediğinizde kullanılır. Çoğu zaman, belirli bir içeriğe sahip dosyaları bulmaya çalışırız. Örneğin içerisinde “forensics” kelimesi geçen tüm dosyaları isteriz. Bu durumda mantıksal dosya aramayı kullanırız. Bu işlem mantıksal dosya sistemi aramasına benzerdir. Ancak bu teknikte veri birimlerini kullanıldıkları dosyalara göre bir sıralamayla ararız volumedeki sıralarına göre değil. Bunu aşağıdaki şekilde görebiliriz.
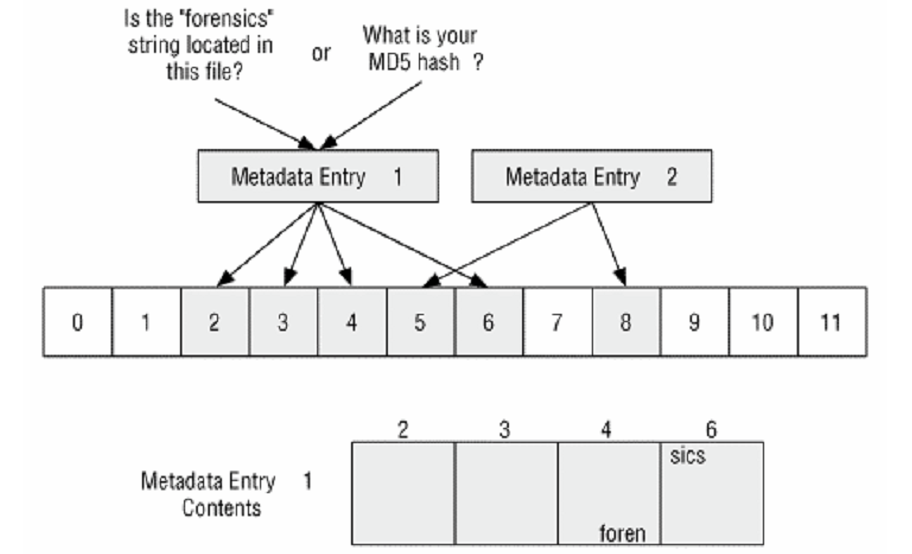
Burada 2 metadata girdisi ve bu girdilerin atandığı veri birimleri bulunmaktadır. Bu durumda; 2, 3, 4 ve 6 numaralı veri birimlerini bir dizi halinde ararız. Bu aramanın mantıksal dosya sistemi aramasından üstün tarafı, çapraz-bölünmüş (cross-fragmented) veri birimlerini veya sektörleri de bulabilmesidir. Bu tip aramanın bir diğer çeşidi ise dosyayı MD5 veya SHA-1 hash değerine göre aramaktır.
Sadece atanmış veri birimlerinin mantıksal dosya adresi vardır. Bu yüzden, aynı değer için atanmamış veri birimlerinin mantıksal volume aramasını yapmak da gerekir. Örneğin bir mantıksal dosya araması yukarıdaki örnekte 0 ve 1 numaralı veri birimlerini aramaz.0,1,7,9,10,11’i içeren ikinci bir arama yapmak zorundayız.
Metadata özniteliği arama ve sıralama
Bir dosya, metadata değerlerinden birine göre de aranabilir. Bu bölümde bu tip aramayı gerektirebilen birkaç örneğe göz atacağız. Dosya zamanları kolaylıkla değiştirile bilinmesine rağmen, birçok kanıt içerebilir. Örneğin, bir saldırganın saat 8:13’te bilgisayara giriş yapıp saldırı tool’ları yüklediğine ilişkin bir hipotezimiz varsa, biz bu hipotezimizi, saat 8:13 ile 8:23 arasında yaratılmış dosyaları arayarak test edebiliriz. Bu zaman aralığında yaratılmış herhangi bir dosya bulamazsak ancak farklı bir zamanda yaratılmış saldırı tool’ları bulursak, ya zaman bilgileri, ya hipotezimiz ya da ikisi birden hatalıdır. Hakkında çok az şey bildiğiniz bir bilgisayarla karşılaştığınızda geçici veriler de yararlı olabilir. Geçici veriler, son zamanlarda hangi dosyalara erişilmiş ve yaratılmış gibi bilgileri gösterir. Bu, bilgisayarın nasıl kullanıldığına dair bize ipuçları verir. Bazı tool’lar bize dosya aktivitesine dair bir zaman çizelgesi yaratır. Çoğu çizelgede, bir dosyanın birden fazla girdisi olabilir. Örneğin, dosyaya ait son erişim, son yazım ve son modifiye edilme tarihi varsa, zaman çizelgesinde üç girdiye sahip olur.
Birden fazla bilgisayardaki log girdileri ve dosya zamanlarını birbirleriyle ilişkilendirmeden önce, bir dosya sisteminin zaman damgalarını (time stamps) nasıl sakladığını anlamak gerekir. Bazı zaman damgaları UTC (Coordinated Universal Time) olarak saklanır. Yani gerçek zamanı bilebilmek için bilgisayarın bulunduğu zaman dilimimdeki saat farkını bilmeniz gerekir. Örneğin, Boston’da saat 2’de bilgisayara giriş yaptıysam bilgisayar bunu 7 olarak kaydeder çünkü Boston,UTC’ye göre 5 saat geridedir. Bazı dosya sistemleri ise yerel zaman dilimine göre saklar. Örneğin, yukarıdaki örneği ele aldığımızda bilgisayar, zamanı, 2 olarak kaydeder.
Daha önceden bir mantıksal dosya sistemi araması yaptıysak ve veri birimlerinin birinde ilginç bir veri bulduysak, ilgili veri birimi adresine dair metadata girdilerini de aramak isteyebiliriz. Bu arama bize, hangi dosyanın veri birimine atanmış olduğunu gösterebilir ve bu sayede aynı dosyaya ait diğer veri birimlerini bulabiliriz.
Tutarlılık Kontrolü
Metadata’yla yapılan bir tutarlılık kontrolü, veri gizleme girişimlerini veya dosya sistemi imajının, bilgileri doğru olarak görmemizi engelleyecek içsel hatalara sahip olup olmadığını ortaya çıkarabilir. Yapılabilecek kontrollerden biri, her atanmış girdiyi inceleyerek o girdilere atanmış veri birimlerinin de atanmış olup olmadığını kontrol etmektir. Bu işlem, atanmış veri birimlerinin sayısı ile dosyanın boyutunun birbiriyle tutarlı olduğunu doğrulamalıdır. Ayrıca özel tipteki dosyalara ait girdilere atanmış veri birimleri bulunmadığını da doğrulamalıyız. Örneğin bazı dosya sistemlerinde “soket” adı verilen, süreçler tarafından, diğer süreçlerle iletişimde bulunmak için kullanılan özel dosyalar vardır ve bu dosyalar herhangi bir veri birimine atanmazlar.
Wipe teknikleri
Bir dosya silindiğinde zaman, boyut ve veri birimi adresleri gibi metadata bilgileri sıfırlarla veya rastgele verilerle wipe edilebilir. Bir araştırmacı, iki geçerli girdi arasında, sıfırlarla doldurulmuş veya geçerli olmayan girdilere bakarak wipe işlemini tespit edebilir. Daha ileri düzey bir wipe aracı, wipe edilecek değerlerin yerini orijinal dosyayla alakası olmayan geçerli verilerle doldurabilir. Daha da ileri düzey metadata wipe aracı ise geriye kalan girdileri silinecek girdiye doğru kaydırarak kullanılmayan girdi kalmamasını sağlayabilirler.
Dosya İsmi Kategorisi
Bu veri kategorisi sadece bir dosyanın ismini ve metadata adresini içerir. Dosya ismi analizinin önemli bir kısmı, kaynak dizinin nerede olduğunu saptamaktır. Çünkü tam erişim belirteci verilen bir dosyayı bulurken ona ihtiyacımız vardır.
Genel bilgiler
Dosya ismine dayalı dosya kurtarma
Dosya ismine dayalı kurtarmada, silinmiş dosya ismi ve onla ilişkili metadata adresini kullanarak, metadata tabanlı kurtarma ile dosya içeriğini geri getirebiliriz. Diğer bir deyişle, bütün ağır işlem metadata katmanında yapılır ve bu katmanda yaptığımız tüm iş odaklanacağımız metadata girdilerini tanımlamaktır. Aşağıdaki şekilde 2 dosya ismimiz ve 3 metadata girdimiz vardır.
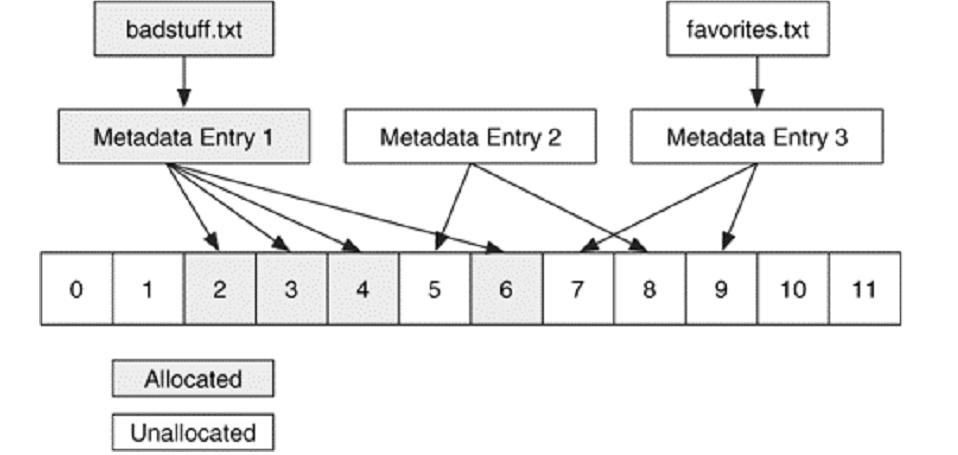
Şekilde “favorites.txt” dosyası silinmiş ve ismi, atanmamış bir metadata girdisini göstermektedir. Bu dosyanın içeriğini metadata tabanlı kurtarma teknikleriyle kurtarmayı deneyebiliriz. Aşağıdaki şekil, metadatanın tekrardan atanmasından önce, veri birimlerinin tekrardan atanması nedeniyle kurtarmanın ne kadar karmaşıklaştığını göstermektedir.
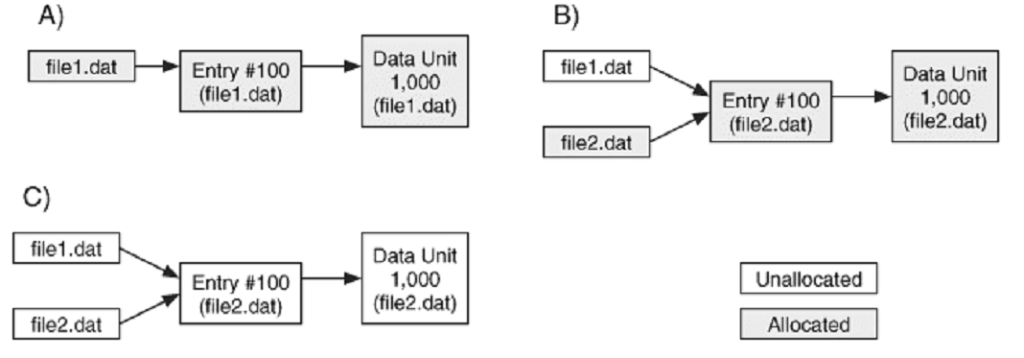
Metadata girdisi 100’ü gösteren bir “file1.dat” dosyası olduğunu varsayalım. (A) Bu dosya silinmiş ve dosya ismi ile metadata yapıları atanmamış duruma geçirilmiş fakat dosya ismi veri yapısındaki işaretçi (pointer) wipe edilmemiş. Sonrasında yeni bir dosya isim yapısı içerisinde ”file2.dat” isminde yeni bir dosya yaratılmış ve bu dosya metadata girdisi 100’ü tekrardan atıyor. (B) Daha sonra ise, “file2.dat” dosyası da silinerek dosya ismi ve metadata yapıları atanmamış duruma geçiriliyor. (C) Eğer bu durumdayken sistemi incelersek, aynı metadata girdisini gösteren iki adet atanmamış dosya ismi buluruz. Bu yüzden metadata girdisi 100 tarafından gösterilen içeriğin ”file1.dat” için mi yoksa “file2.dat” için mi olduğunu bilemeyiz.
Bazen bundan daha karışık durumlarla da karşılaşabiliriz. Bu yüzden, silinmiş dosyaları dosya ismi perspektifiyle incelerken, metadata ve veri birimlerinin yeni bir dosyaya atanmış olabileceğini de düşünmeliyiz.
Analiz teknikleri
Dosya ismi listeleme
En yaygın kullanılan inceleme tekniklerinden biri dosya ve dizinlerin isimlerini listelemektir. Bunu, isme, yola (path) veya dosya uzantısına dayalı olarak kanıt aradığımız durumlarda kullanırız. Çoğu dosya sistemi, silinen bir dosyaya ait dosya ismini temizlemez. Böylece listelemede silinmiş dosya isimleri de görülebilir. Bazı durumlardaysa bir dosya silindiğinde metadata adresi de silinir ve dosya hakkında daha fazla bilgi edinemezsiniz. Bu tekniğin ardındaki temel teori; ilk önce kaynak dizinin yerini bulmaktır. Kaynak dizinin yapısı bir metadata girdisinde bulunur ve biz, bu girdi ile dizinin atanmış olduğu veri birimlerinin yerlerini bulmalıyız. Dizin içeriğini bulduktan sonra, bu içeriği işleyerek dosyaların ve ilgili metadata yapılarının bir listesini elde etmeliyiz. Eğer bir kullanıcı listelenmiş olan bir dosyanın içeriğini görmek isterse, listelenen metadata adresleri aracılığıyla mantıksal dosya görüntülemeyi kullanabiliriz. Aşağıdaki şekilde bu analiz sürecine bir örnek gösterilmiştir.
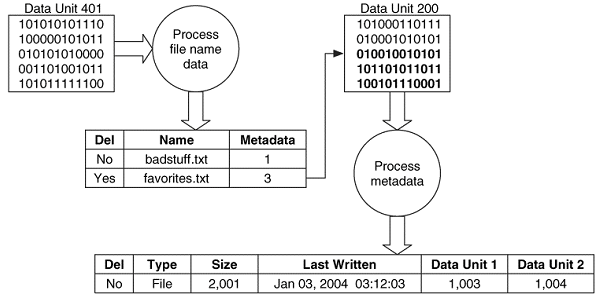
Burada veri birimi 401 incelenerek 2 dosya ismi bulunmuştur. Bizi ilgilendiren dosya, “favorites.txt” dosyasıdır ve bu dosyanın metadatası 3.girdidedir. Bizim buradaki dosya sistemimiz metadata yapısını veri birimi 200’de saklamaktadır. Bu yüzden, veri birimi 200’deki ilgili veriyi işleyerek dosyanın boyutunu ve içerik adreslerini öğreniriz.
Dosya ismi listeleme
Hangi dosyayı aradığımızı biliyorsak, dosya isimlerini listelemek uygun bir yöntem olabilir. Ancak bu durum her zaman geçerli değildir. Eğer dosya isminin tamamını bilmiyorsak, bildiğimiz kısımları arayabiliriz. Örneğin, dosya uzantısını veya ismini biliyor ancak tam olarak dosya yolunu bilmiyor olabiliriz. Bu durumda elimizdeki bilgileri kullanarak bir arama yapabiliriz. Ancak dosya uzantısına göre yapılan aramalar, her zaman aradığımız uzantıya sahip dosyaları bize getirmeyebilir çünkü dosyayı gizlemek amacıyla dosya uzantısı değiştirilmiş olabilir. İsme göre arama işlemi dosya ismi listelemede gördüklerimizle benzerdir. Bir dizine ait içeriği yükler ve işleriz. Dizindeki her girdiyi aradığımız kalıpla karşılaştırırız. Bu kategorideki diğer bir arama ise, bilinen bir metadata girdisine atanmış dosyanın ismini aramaktır. Bu, bir veri biriminde kanıt bulup bu birime atanmış olan metadata yapısını aramak istediğiniz durumlarda kullanılır.
Veri yapısı atama sırası
İki isim arasındaki bağıl yaratılma zamanını bulmak için dosya isim yapılarının atanma sırası kullanılabilir. Bu işlem işletim sistemine bağımlıdır.
Tutarlılık kontrolü
Dosya isim verisi için tutarlılık kontrolü, bütün atanmış isimlerin, atanmış metadata yapılarını gösterdiğini kontrol eder.
Wipe teknikleri
Bu kategorideki bir wipe aracı, isim ve metadata bilgilerini temizler. Wipe tekniklerinden biri, dosya isim yapısındaki değerlerin üzerine yazmaktır. Bu sayede, yapılan bir analiz girdinin var olduğunu ancak içerisindeki verinin geçerli olmadığını gösterir. Örneğin, ”setuplog.txt” dosya ismi000 “abcdefg.123” ile değiştirilebilir.
Diğer bir teknik ise isim listesini yeniden organize ederek silinen dosya isminin üzerine var olan dosya isimlerinden birini yazmaktır. Bu, ilk metottan daha karmaşık ve çok daha etkilidir çünkü araştırmacı, bu dizinde sıra dışı bir durum olduğunu asla anlayamayabilir.
Uygulama Kategorisi
Dosya sistemi günlükleri
Eğer işletim sistemi, diske veri yazıyor veya diske veri yazmak için bekliyorken çökerse, dosya sistemi tutarsız durumda olur. Atanmış bir metadata yapısı ile atanmış veri yapıları varken, bunların arasındaki işaretçiler veya metadata yapısını gösteren bir dosya ismi bulunmayabilir.
Tutarsızlıkları tespit etmek için, işletim sistemi, dosya sistemini tarayarak, kayıp işaretçiler ile diğer çökme belirtilerini arayan bir program çalıştırır. Tarama programının işini kolaylaştırmak için, bazı dosya sistemleri bir günlük oluşturur. Dosya sisteminde herhangi bir metadata değişikliği yapılmadan önce günlükte, yapılacak değişikliği tanımlayan bir girdi oluşturulur. Değişiklik yapıldıktan sonra ise günlükte, değişikliklerin yapıldığına dair bir girdi daha oluşturulur. Eğer sistem çökerse, tarama programı günlüğü okur ve tamamlanmamış olan girdilerin yerlerini belirler. Sonrasında ise ya değişiklikleri tamamlar ya da orijinal duruma geri döndürür. Dosya sistemi günlükleri, zaman bilgilerinin tamamen değiştirilebilmesine rağmen, incelemelerde kullanışlı olmaktadır. Bir günlük, yakın zamanda hangi dosya sistemi olaylarının gerçekleştiğini gösterir ve bu olay yeniden yapılandırması esnasında oldukça yardımcı olur.
Uygulama Seviyesi Arama Teknikleri:
Uygulama tabanlı dosya kurtarma (Data Carving)
Bu, bir veri kümesinde, bilinen dosya türlerinin başlangıç ve bitişi anlamına gelen “imza”ların aranması sürecidir. Örneğin, bir JPEG resminin standart başlık ve bitiş değerleri vardır. Bir araştırmacı, silinmiş resimleri geri getirmek istediğinde, atanmamış alanı çıkartarak, JPEG başlığı arayan bir carving aracı çalıştırır ve başlık ile bitiş değeri arasındaki veriyi alır. Aşağıdaki şekilde 902. sektörünün ilk 2 byte’ında JPEG başlığı ve 905. sektörün ortalarında JPEG bitiş değeri taşıyan bir veri dizisini göstermektedir.

902, 903 ve 904. sektörler ile 905. sektörün baş kısmı bir JPEG resmi olarak çıkartılabilir.
Dosya tipi sıralama
Bir dosya sistemindeki dosyaları organize etmek için dosya tipi de kullanılabilir. Eğer araştırmada, özel tipte bir veri aranıyorsa, araştırmacı, dosyaları içerik yapılarına göre sıralayabilir.
Özel Dosya Sistemleri
Aşağıdaki tablo, bu kitaptaki dosya sistemleri için, her veri kategorisindeki veri yapısı isimlerini içermektedir.

Yazar: Öğr.Gör. Dr. Baki NAKKAŞ





